
La macchina del tempo non è solo un sogno per gli amanti dell'avventura. E' anche una necessità per chi vuole mantenere il controllo della configurazione del contenuto in un server nel tempo.
Mai cancellato o sovrascritto accidentalmente un file su cui stavi lavorando? Mai perso dati a causa di guasto del disco rigido?
Non sarebbe bello se ci fosse una directory che contiene tante "fotografie" del nostro prezioso filesystem scattate a distanza di poche ore?
E se tutto questo potesse avvenire utilizzando poco spazio senza duplicare inutilmente file e in poco tempo e senza alcun utilizzo di tool specifici?
Questo articolo prende spunto da uno scritto di Mike Rubel in cui si descrive come realizzare questa magia utilizzando alcuni strumenti disponibili liberamente su Unix da moltissimi anni: gli hard links e rsync.
L'utilizzo di hard link permette di minimizzare lo spazio su disco necessario per memorizzare gli snapshot. Di fatto è utilizzato solo lo spazio necessario per memorizzare le differenze tra due "fotografie" successive, un po' come avviene nei backup incrementali. Il risultato è straordinariamente sicuro, semplice ed efficace. Difficilmente un tool di backup vi consentirà tanto controllo.
In particolare questo articolo propone una versione migliorata dello script presentato da Mike e una piccola estensione per la gestione dei database. Lo script è stato testato su Ubuntu ma non dovrebbe avere problemi a girare in un qualunque ambiente linux/unix.
Prerequisiti
L'unico pre-requisito allo script è la disponibilità di rsync. Su ubuntu è possibile installarlo con il comando:
apt-get install rsync
Lo script
Rispetto a quello di Mike (cui si rimanda per i dettagli) questo script:
- consente memorizzare le snapshot sia su un filesystem montato in read-only sia in locale
- gestisce un numero arbitrario di snapshot
- salva un log dei file modificati insieme alla snapshot
Lo script può essere configurato modificando alcuni parametri ed in particolare :
- SNAPSHOT_DIR è il nome della directory in cui verranno memorizzate le snapshot
- SNAPSHOTNAME è il prefisso della snapshot. Se si sceglie, ad esempio il nome "mirror" la snapshot più recente sarà mirror.0 mentre mirror.1 sarà la seconda snapshot più recente, mirror.2 la terza e così via.
- MAXSNAPSHOT determina il numero di massimo snapshot sequenziali. Con questo parametro si forza un tetto al numero di snapshot possibili, le snapshot più vecchie vengono cancellate.
- SRCS è l'elenco delle directory che si desidera fotografare. E' consigliabile usare sempre pathname assoluti. Le directory devono essere separate da uno spazio o da un tab
- EXCLUDES contiene il pathname di un file che, a sua volta, contiene una per riga delle espressioni con wildcard (vedi la documentazione di rsync del parametro --exclude-from=FILE). Tutti i file che corrispondo ad almeno una espressione nel file NON sono fotografati. Tipicamente è bene inserire in questo file tutte le directory temporanee e di cache. Ad esempio:
*/cache/*
*/tmp/*
In accordo con i consigli di Mike è preferibile memorizzare le snapshot in un file system montato normalmente in read-only. Chiaramente in questo caso, prima di eseguire la snapshot è necessario rimontare il filesystem in read-write per poi riportarlo in read-only alla fine dello script. Il device da montare è contenuto nella variabile MOUNT_DEVICE. Se tale variabile è omessa, non viene eseguito il codice che si preoccupa di montare il filesystem.
Ecco dunque tutto lo script:
#!/bin/bash
# ----------------------------------------------------------------------
# Questo indirizzo email è protetto dagli spambots. È necessario abilitare JavaScript per vederlo. based on
# mikes handy rotating-filesystem-snapshot utility
# see http://www.mikerubel.org/computers/rsync_snapshots/
# ----------------------------------------------------------------------
# the basic idea is it makes
# rotating backup-snapshots of /home whenever called
# ----------------------------------------------------------------------
# ------------- config params ------------------------------------------
#MAXSNAPSHOT= max number of available snapshots (from 0)
MAXSNAPSHOT=3;
#SNAPSHOTNAME= the base name for the snapshot
SNAPSHOTNAME="daily";
#SNAPSHOT_DIR= target directory for snapshots
SNAPSHOT_DIR="/mnt/mirrors";
#SRCS= directories we want to backup (absolute path)
SRCS="/home /etc /var/db-snapshots";
#EXCLUDES= file containig rsync exclusion
EXCLUDES="/etc/snapshot_exclude";
#MOUNT_DEVICE= the device to be mounted in order to access SNAPSHOT_DIR,
#if undefined, or MOUNT_DEVICE is not a block device no mount occurs
#MOUNT_DEVICE=/dev/hdb1;
# ------------- system commands used by this script --------------------
unset PATH # suggestion from H. Milz: avoid accidental use of $PATH
MOUNT=/bin/mount;
ID=/usr/bin/id;
ECHO=/bin/echo;
GREP=/bin/grep;
RM=/bin/rm;
MV=/bin/mv;
CP=/bin/cp;
MKDIR=/bin/mkdir;
TOUCH=/bin/touch;
RSYNC=/usr/bin/rsync;
# ------------- the script itself --------------------------------------
# make sure we're running as root
if (( `$ID -u` != 0 )); then { $ECHO "Sorry, must be root. Exiting..."; exit; } fi
# makesure SNAPSHOT_DIR exists
$MKDIR -p $SNAPSHOT_DIR
# if defined MOUNT_DEVICE attempt to remount the RW mount point as RW; else abort
if [ -b "$MOUNT_DEVICE" ]; then
# If fs not mounted , mount it else remount it in rw
if [ -z "$($GREP $MOUNT_DEVICE /proc/mounts | $GREP $SNAPSHOT_DIR)" ]; then
$MOUNT $MOUNT_DEVICE $SNAPSHOT_DIR ;
else
$MOUNT -o remount,rw $MOUNT_DEVICE $SNAPSHOT_DIR ;
fi
if (( $? )); then
$ECHO "snapshot: could not mount $SNAPSHOT_DIR readwrite";
exit;
fi
fi
# rotating snapshots
# step 1: delete the oldest snapshot, if it exists:
if [ -d $SNAPSHOT_DIR/$SNAPSHOTNAME.$MAXSNAPSHOT ] ; then \
$RM -rf $SNAPSHOT_DIR/$SNAPSHOTNAME.$MAXSNAPSHOT ; \
fi ;
# step 2: shift the middle snapshots(s) back by one, if they exist
# Example , if MAXSNAPSHOT =3 the loop runs:
# if [ -d daily.2 ] ; then mv daily.2 daily.3 ; fi;
# if [ -d daily.1 ] ; then mv daily.1 daily.2 ; fi;
i=$MAXSNAPSHOT;
while [ $i -gt 1 ]
do
j=$i;
let i=i-1;
if [ -d $SNAPSHOT_DIR/$SNAPSHOTNAME.$i ] ; then
$MV $SNAPSHOT_DIR/$SNAPSHOTNAME.$i $SNAPSHOT_DIR/$SNAPSHOTNAME.$j ;
fi;
done
# step 3: make a hard-link-only (except for dirs) copy of the latest snapshot,
# if that exists
if [ -d $SNAPSHOT_DIR/$SNAPSHOTNAME.0 ] ; then \
$CP -al $SNAPSHOT_DIR/$SNAPSHOTNAME.0 $SNAPSHOT_DIR/$SNAPSHOTNAME.1 ; \
fi;
# step 4: rsync from the system into the latest snapshot (notice that
# rsync behaves like cp --remove-destination by default, so the destination
# is unlinked first. If it were not so, this would copy over the other
# snapshot(s) too!
# - ensure that EXCLUDES exists
$TOUCH $EXCLUDES
$RSYNC -a --delete --delete-excluded --exclude-from="$EXCLUDES" \
--log-file="/tmp/make_snapshot.log" $SRCS $SNAPSHOT_DIR/$SNAPSHOTNAME.0
$MV /tmp/make_snapshot.log $SNAPSHOT_DIR/$SNAPSHOTNAME.0
# step 5: update the mtime of $SNAPSHOTNAME.0 to reflect the snapshot time
$TOUCH $SNAPSHOT_DIR/$SNAPSHOTNAME.0 ;
# now remount the RW snapshot mountpoint as readonly
if [ -b "$MOUNT_DEVICE" ]; then
$MOUNT -o remount,ro $MOUNT_DEVICE $SNAPSHOT_DIR ;
if (( $? )); then
{
$ECHO "snapshot: could not remount $SNAPSHOT_DIR readonly";
exit;
} fi
fi
Come lanciare lo script
Il modo più semplice è quello copiare lo script nella directory cron.daily. In questo modo lo script produrrà ogni giorno una snapshot dei nostri file. E' anche possibile inserirlo nella directory cron.hourly se si vuole avere una snapshot ogni ora oppure in cron.weekly se si vuole una snapshot a settimana. Nulla vieta di avere alcuni file fotografati ogni ora, altri ogni giorno, altri ancora ogni settimana. Chi è capace di usare direttamente cron può decidere policy ancora più sofisticate.
E il database?
Un modo semplice di gestire il backup del database MySQL è quello di inserire tra le directory da fotografare anche la directory che contiene le tabelle e gli indici. In ubuntu è /var/lib/mysql.
Prima però, occorre garantirsi che i file siano consistenti durante tutto il processo di backup. Un metodo è quello sintetizzato nei seguenti step:
- mysql connection (left open): FLUSH TABLES WITH READ LOCK;
- eseguire lo script inserendo tra le directory da fotografare /var/lib/mysqlmy
- sql connection: UNLOCK TABLES;
I controdi questa soluzione sono:
- il db rimane lockato per tutta la durata di esecuzione dello script.
- L'eventuale restore dei dati può avvenire utilizzando la tabella (ma meglio il db) come grana minima.
Una soluzione più semplice e sicura consiste nel eseguire un altro script che esegue il dump del database in alcuni file in una directory coperta dallo script che fa le snapshot. Ecco come:
#!/bin/bash
# ----------------------------------------------------------------------
# 20101118 Questo indirizzo email è protetto dagli spambots. È necessario abilitare JavaScript per vederlo.
# ----------------------------------------------------------------------
# this scripts create a snapshot foreach db defined in mysql
# ----------------------------------------------------------------------
unset PATH
# ------------- system commands used by this script --------------------
ID=/usr/bin/id;
ECHO=/bin/echo;
MKDIR=/bin/mkdir;
MYSQL=/usr/bin/mysql;
MYSQLDUMP=/usr/bin/mysqldump;
GZIP=/bin/gzip;
# ------------- file locations -----------------------------------------
#SNAPSHOT_DB= where to put db snapshots
SNAPSHOT_DB="/var/db-snapshots";
# ------------- the script itself --------------------------------------
# make sure we're running as root
if (( `$ID -u` != 0 )); then { $ECHO "Sorry, must be root. Exiting..."; exit; } fi
# makesure SNAPSHOT_DB exists
$MKDIR -p $SNAPSHOT_DB
DATABASES=$( $ECHO "show databases" | $MYSQL --skip-column-names )
for DATABASE in $DATABASES
do
if [ "$DATABASE" != "information_schema" ] ; then
$MYSQLDUMP $DATABASE | $GZIP > "$SNAPSHOT_DB/$DATABASE.sql.gz"
fi;
done
Chiaramente questo script va eseguito subito prima di fare le snapshot delle directory.
Per evitare che lo script chieda la password create il file /root/.my.cnf con il seguente contenuto.
[client]
user=root
password=mysqlrootpassword
Non dimenticate infine di rendere il file leggibile solo a root:
sudo chmod 600 /root/.my.cnf
I pro di questa soluzione sono:
- non richiede un lock delle tabelle (a meno che non si desideri una assoluta sincronizzazione temporale tra file e db)
- i file creati possono essere restorati anche su un'altro db, anche di differenti versioni. Trattandosi di file SQL è anche possibile fare restore parziali.
I contro sono:
- i file di dump sono sempre nuovi. Il meccanismo degli hard link, utilizzati per minimizzare lo spazio su disco necessario alla snapshot, in questo caso non offre nessun vantaggio: ogni snapshot del db "pesa" infatti come l'intero db compresso.
- lo script è cpu e db intensive. Di fatto è consigliabile solo per db di modesta entità.
In ogni caso entrambe le soluzioni sono lontane dall'essere perfette. La soluzione più completa richiede la sincrornizzazione del db tra due istanze di cui la copia slave è memorizzata su un filesystem che gestisce la deduplicazione. Ma questa è un'altra storia (vedi capitoli sucessivi). Se qualcuno ha un'altra idea, meno costosa, non esiti a segnalarla nelle note.
Considerazioni sugli inode
Non di solo spazio vive un disco, ma anche di inode. Un inode serve per memorizzare un puntatore ad un area di memoria che contiene i dati. Sostanzialmente potete pensarlo come il nome del file. Il numero di Inode in un filesystem è limitato, alcuni filesystem consentono la modifica di tale numero dinamicamente, altri solo al momento della formattazione.
Normalmente il numero di inode è dimensionato durante la formattazione del disco tenendo conto della dimensione dei blocchi disponibili. Se usiamo il meccanismo di snapshot, rispetto all'uso normale, usiamo pochi blocchi ma molti inode. E' probabile quindi che il conto di default sia sbagliato.
Nella formattazione del disco target per le snapshot dimesionate correttamente il numero di Inode
Verificate il numero di inode disponibili con il comando:
df -i
Il numero di inode dovrebbe quello utilizzato dai filesystem che stiamo backuppando moltiplicato il numero di snapshot.
Performances
Lo script, eseguito la prima volta su una macchina con circa 1GB di Ram disponibile, con un core Xeon a 1Mhz ha fotografato un filesystem di 1200MB e 120000 files in circa 3minuti su un disco esterno collegato ad alta velocità.
Lo stesso comando ripetuto una seconda volta ha ricostruito l'immagine dello stesso filesystem in circa 35 secondi trasferendo solo 2MB (relativa alla struttura delle directory e dei file modificati tra un run e l'altro).
Nonostante nel disco esterno siano presenti due fotografie complete del filesystem, grazie all'uso degli hardlink, lo spazio fisicamente allocato sul disco è sostanzialmente immutato tra le due run.
Nel mio caso 20 snapshots effettuate a distanza di un giorno dall'altro hanno occupato spazio pari circa al doppio dello spazio necessario per una sola copia fisica.
Una "Corporate Time machine"
Lo script proposto nei capitoli precedenti è una dimostrazione di come sia sostanzialmente semplice ed economico gestire una "tima machine", ovvero un meccanismo di snapshot incrementali di un file system, su un server linux.
E' possibile applicare lo stesso approccio su scala aziendale. In questo caso però serve qualcosa di più sofisticato:
- Occorre spezzare lo script separando la gestione di rdist dalla rotazione delle snapshot. Questo consente di utilizzare come target per le snapshot una macchina remota. La macchina avrà la funzione di backup center per più server e risorse locali. I client devono avere solo rdist e un meccanismo di scheduling.
- Occorre integrare la gestione degli snapshot basata su hard link con di tecnologie di data deduplication e di database replication. Ad esempio il filesystem ZFS di Sun o S3 di Amazon. La deduplicazione ha indubbi vantaggi, sopratutto per la gestione di grandi file che cambiano spesso (es. log e db)
- Gestire in un modo specifico la replica del db.
- Gestire snapshot a grana temporale crescente. Ad esempio una snapshot basato su hard link ogni 4 ore per tutta la giornata sui file, l'ultima snaphot della giornata viene mantenuta per sette giorni (tramite hardlink), viene mantenuta una snapshot per ognuna delle ultime tre settimane precedenti e una per ognuno dei tre mesi precedenti.
- Selezionare la tecnologia di snapshot più opportuna per la tipologia dei file e la grana temporale. Ad esempio usare gli hardlink per le snapshot giornaliere dei piccoli file, usare repliche e deduplication per i grandi db
La soluzione più flessibile consiste nell'integrare tutti gli approcci: periodicamente eseguire rdist localmente a uno o più filesystem salvando i dati su una macchina remota; sulla macchina remota gestire i processi di costruzione delle snapshot utilizzando sia gli hard link che database replication e data deduplication. Il tutto utilizzando servizi di cloud computing.
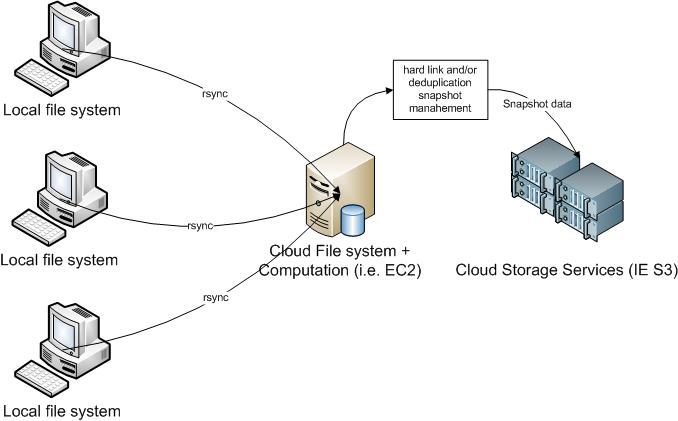
Su scala aziendale è però fondamentale progettare la soluzione (o il servizio) analizzando con cura le specifiche esigenze, in paricolare tenendo conto di:
- requisiti di sicurezza e gestione del rischio
- frequenza di backup differenziata su diverse tipologie di dati dati
- tecnologia e dimensioni dei database
- gestione dei file di log
- integrazione con politiche di backup locali
- capacità della infrastuttura di rete della azienda
- predisposizione all'innovazione del management
- maturità dell'IT sulle tecnologie di cloud computing
Appena ci sarà un po' di tempo scriverò un articolo specifico su questi temi. Intanto, se potete, segnalatemi qualche risorsa utile nei commenti